
The binary search algorithm is a powerful technique used in a variety of technology applications, including Git and AWS Kinesis. By using bisect method, it simplifies your day-to-day tasks and improves performance. In this article, we will dive into the details of how the binary search algorithm works and how it can be implemented in your own projects. Understanding the concepts behind the binary search algorithm is essential for any developer looking to improve their skills. The binary search algorithm is a key tool in computer science, helping to make search operations more efficient. It can be used to search for a specific value in a sorted list of values, allowing for faster and more accurate results. In Git, the bisect command uses the binary search algorithm to find the exact commit that introduced a bug. In AWS Kinesis, the algorithm helps to process and analyze streaming data in real-time. By the end of this article, you will have a solid understanding of the binary search algorithm and how it can be used to improve your own projects.
From Wikipedia:
“In computer science, binary search … is a search algorithm that finds the position of a target value within a sorted array. If they are not equal, the half in which the target cannot lie is eliminated and the search continues on the remaining half, again taking the middle element to compare to the target value, and repeating this until the target value is found.”
Pretty simple, right? Find the middle element -> compare the value -> divide again by half until you find your target.
Use case 1: Troubleshooting bad deployments
If you are using Git for your source version control (I bet you do) and you have fixed manual release cycles (I hope you don’t), then git bisect command can become your best friend. Let’s imagine your team has the following process:
- Your company has a requirement to release new code every 2 weeks
- The dev team has set up dev branch where they commit their work
- Every 2 weeks, the dev team cuts the release candidate branch (basically a snapshot of all the work done in the last sprint) and hands it over to the QA team that is responsible to test it during the next 2 weeks
- The dev team continues to commit work for the next release cycle while pushing some code to the release candidate branch if QA found some bugs
This is a happy case scenario when the new release candidate does not have any bugs (no way!) or the dev team accomplished fixing all customer-visible bugs by the end of the release cycle (more realistic). But what if there was some last-minute bug and you don’t have time left to patch it? And the more scary scenario – what if you don’t know what commit exactly caused this bug/regression? and the scariest part – what if all your teammates went on vacation for the Christmas holidays, and there is no subject matter expert to help? Don’t worry, I have a solution for you!
git bisect command uses the same principle as binary search. Imagine that your release candidate branch is an array where commits are the values that can take either 0 or 1 (0 is a good commit, and 1 is a bad one). And of course, this array will be always sorted! Our goal is to find the first rotten commit that ruined all the joy and happiness of your holiday season and roll it back or patch or truncate the release candidate branch to the length of good commits sub-array.
First, let’s start with a review of the command API – with git bisect you would usually need only 3 commands:
git bisect start <release_candidate_branch>starts the wizard on the branchgit bisect bad [<commit_hash>]gives git a hint that it needs to move further halfway to the leftgit bisect good [<commit_hash>]gives git a hint that it needs to move further halfway to the right
Note: <commit_hash> is optional and can be specified in the initial command after the start so git will know the range of the search array.
Make sure you have your runtime environment up and running to verify whether the current commit is good or bad. Once git finds the rotten egg (first bad commit after good one), it will stop the execution and let you know.
DISCLAIMER: I had to execute this command only once in my life, and strongly recommend using CI/CD for your deployments. Having a deployment process manual leaves a lot of room for human mistakes – always automate your test processes!
Use case 2: Serverless failure management
I recently finished AWS Serverless Learning Plan (highly recommend attending), and learned that AWS Lambda offers BisectBatchOnFunctionError configuration attribute for stream-based (Kinesis or DynamoDB streams) invocations.
Stream event sources require high throughput processing in real-time (or near-real-time) fashion (imagine, YouTube-like live-stream chat emojis application). To improve this, AWS Kinesis leverages partitioning by distributing incoming events (emojis) to shards. Each shard might have its own Lambda function consumer, which instead of reading events one by one will do it in batches. By default, Kinesis guarantees the order of events – and if one event in the batch fails, the entire batch will be retried. For simplicity, let’s imagine we have 5 events in the batch, and 4th event fails to process.

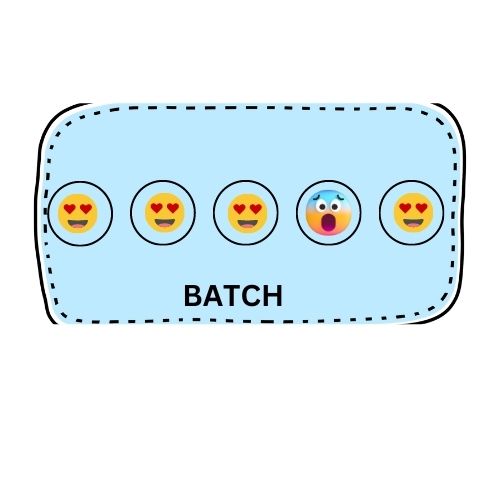
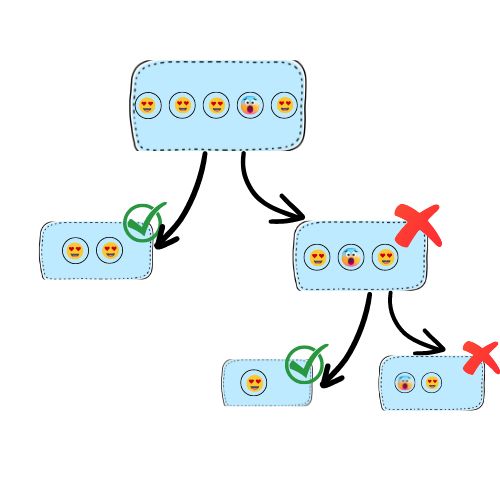
Of course, we can set up max retries and on-failure destination as an error management mechanism for the events but it is not flexible – in this case, we have to do offline error handling for the entire batch. We can be smarter and apply bisect (binary search) here! With one simple configuration, we can tell Lambda to split the failed batch into two batches until eventually, we will find our rotten egg – in this case, we isolate our error only to one event and have to deal with it (however, you need to keep in mind that events going after the bad event in the batch will still be blocked as well as all incoming events in the shard)!

Conclusion
Algorithms is part of our life even if we as engineers do not have to apply them during our routine coding. You probably don’t have to write Dijkstra’s algorithms and solve NP problems every day, but as consumers of different products (libraries, tools, Cloud resources) you need to have some high level understanding of how they work behind the scenes.
You can find relevant articles by searching in “Algorithms around us” category.
Discover more from The Same Tech
Subscribe to get the latest posts sent to your email.
Be First to Comment