
One of the most important qualities of Machine Learning systems is their interpretability (or explainability) which is unfortunately ignored by many companies working with AI. Interpretability refers to the ability to understand and explain how an AI system works, how it arrives at its decisions, and why it makes those decisions. Interpretability is essential not only for building trust but also for identifying and addressing any biases or errors in the system. For example, would you trust AI system’s decisions to reject your loan application or provide you with a diagnosis of a serious illness?
While most of us are comfortable with using a microwave without understanding how it works, many don’t feel the same way about AI yet, especially if that AI makes important decisions about their lives.
Designing Machine Learning Systems By Chip Huyen
There are many different techniques for achieving interpretability in AI systems, ranging from simple methods such as visualizing decision trees or feature importance to more complex methods such as generating explanations using natural language processing (NLP) or neural networks. Each technique has its strengths and weaknesses, and the choice of method will depend on the specific application and the level of interpretability required.
Ultimately, the goal of interpretability is to create AI systems that people can trust and understand. By building transparency and accountability into AI systems, we can ensure that they are used ethically and responsibly and benefit society as a whole.
The Importance of Interpretability Across Industries
Interpretability is crucial in various industries, not just finance or healthcare. In the criminal justice system, AI systems are utilized for risk assessment and predictive policing, making interpretability critical. Without understanding how an AI system arrives at a decision or prediction, it is challenging to ensure that the decision is fair and unbiased. A lack of interpretability could lead to discrimination against certain groups, particularly minorities who have historically faced biases in the justice system.
Another example is the automotive industry, where AI is used for self-driving cars. If an AI system makes a mistake, it’s essential to understand why it happened to prevent it from happening again in the future. Moreover, interpretability can help engineers enhance the performance and safety of self-driving cars by identifying areas of improvement in the system.
Furthermore, interpretability is important in the education industry, where AI systems are utilized to predict student performance and recommend personalized learning strategies. If an AI system recommends the wrong learning strategy, students could struggle to achieve their academic goals. Thus, it is crucial to understand how the system makes decisions to ensure that students receive the best possible education.
Interpretability isn’t just optional for most ML use cases in the industry, but a requirement. Obviously, interpretability is not that important if you build a system to recognize cats in the pictures. The higher price of the mistake, the more your system needs to be self-explainable.
Snapshot of AI state
According to AI Index 2019 Report, interpretability and explainability are identified as the most frequently mentioned ethical challenges across 59 Ethical AI principle documents. However, the report also highlights a concerning trend: only 19% of large companies are actively working to improve the explainability of their algorithms, while just 13% are taking steps to mitigate risks to equity and fairness, such as algorithmic bias and discrimination. This suggests that there is still much work to be done in promoting ethical and responsible AI practices across different industries and sectors.

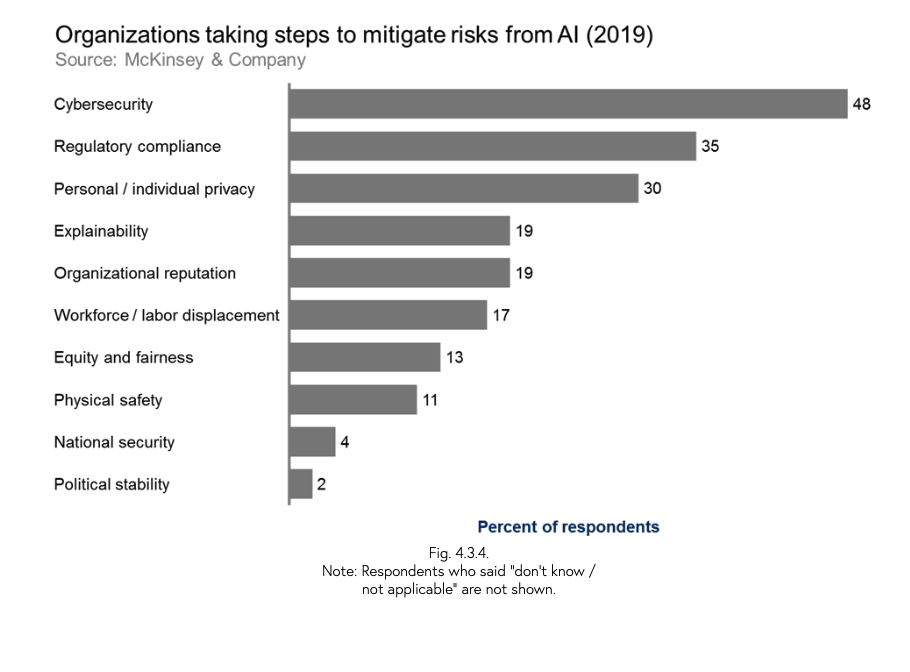
Furthermore, the report notes that there are significant disparities in AI adoption and development between countries, with the United States and China leading in terms of research output and investment. This raises important questions about the global implications of AI and the need for international collaboration and cooperation in shaping its development and governance.
According to the AI Index Report 2021, interpretability and explainability are still considered major challenges in the development and deployment of AI systems. However, the report notes some progress has been made in the last few years in improving the interpretability and explainability of AI systems.

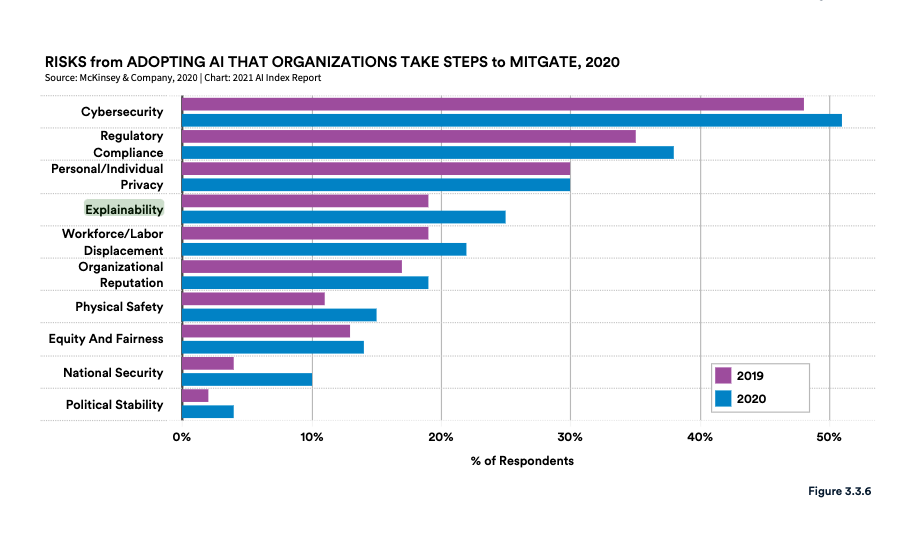
For instance, the report notes that the percentage of papers on explainability and interpretability in AI research has increased significantly in the last few years. Specifically, in 2020, there were 23 accepted papers focused specifically on this topic, while in 2021 this number grew almost 2x times (41 papers).

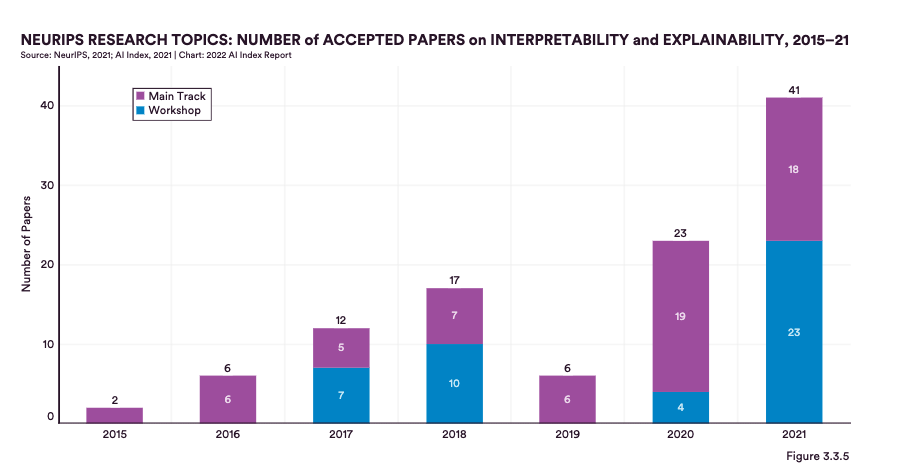
Overall, while there has been some progress in improving the interpretability and explainability of AI systems since the 2019 AI Index Report, there is still much work to be done to ensure that AI systems are transparent, accountable, and trustworthy.
Advancements in Interpretability research
Recent advancements in interpretability research have made significant strides towards improving the transparency and accountability of AI systems. Here are some notable developments:
- Counterfactual explanations: Counterfactual explanations involve generating explanations for a model’s decision by generating a “what-if” scenario where the input data is modified. These explanations can help users understand why a particular decision was made and how it could have been different under different circumstances. Here is a practical example of how to use this technique with ChatGPT.
- Attention-based methods: Attention-based methods aim to provide insight into the inner workings of neural networks by identifying which parts of the input data the network is focusing on during decision-making. These methods can be particularly useful for natural language processing tasks, as they can identify which words or phrases were most important in influencing the model’s output. One example of a system that uses attention-based methods is Google Translate. One of the key features of the Google Translate system is its ability to generate attention maps. These attention maps provide a visual representation of the parts of the input that the neural network is paying the most attention to when making its translations. This allows users to better understand how the system is arriving at its translations and can help to build trust in the system.
- Model distillation: Model distillation involves training a simpler, more interpretable model to mimic the behaviour of a more complex, less interpretable model. By doing so, the simpler model can provide more transparent explanations for the decisions made by the original model. Example: DistilBERT as simplified version of Google’s BERT deep learning model.
- Human-in-the-loop methods: Human-in-the-loop methods involve incorporating human feedback into the interpretability process. For example, a user may be asked to provide feedback on a system’s output, which can then be used to refine and improve the system’s interpretability. The most popular example you use every day is an email spam filter. Many email services use machine learning algorithms to filter out spam emails, but they also rely on user feedback to improve the accuracy of the filters. Users can mark emails as spam or not spam, which the algorithm uses to learn and improve. Recently, OpenAI also added a feedback loop to their ChatGPT language model: whenever you re-generate the answer, the model prompts feedback from you:

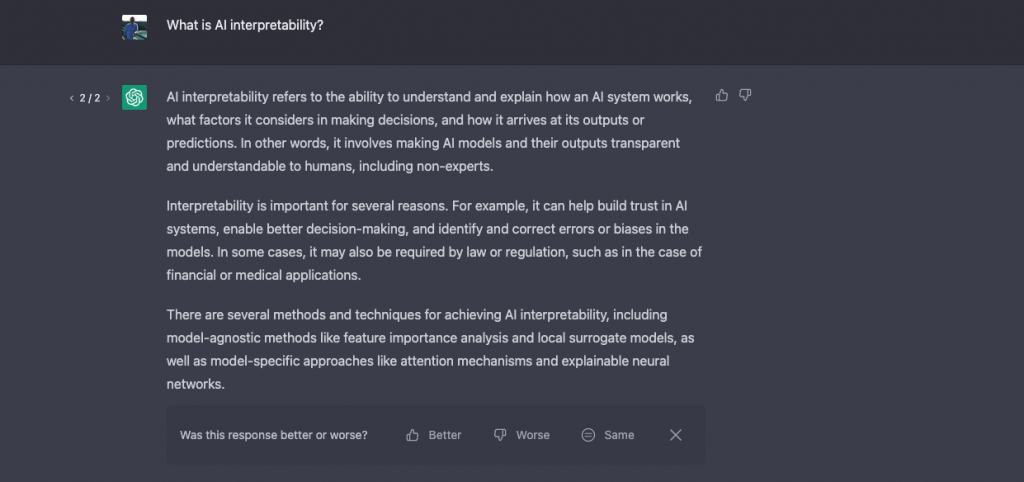
These advancements represent exciting progress towards making AI systems more transparent and accountable. As the field continues to evolve, it’s likely that new techniques and methods will emerge to further improve interpretability and enable users to make more informed decisions based on the output of AI systems.
Interpretability can be harmful
While interpretability can be a valuable tool for understanding AI models and improving trust in their decisions, there are also cases where interpretability can be harmful. In some scenarios, an overly simplified or transparent model can actually compromise privacy and security. For example, in a healthcare context, it may not be desirable for all medical staff to have access to the full details of a patient’s diagnosis and treatment recommendations. In these cases, more opaque models that provide limited access to sensitive information may be preferable.
Another important point to consider is that interpretability can also have negative consequences. For instance, providing too much information about how a system works can make it easier for attackers to identify weaknesses and find workarounds. This can be particularly problematic in sensitive applications, such as financial fraud detection or cybersecurity, where malicious actors could use this knowledge to their advantage.
To illustrate this point, consider the case of Google AdSense, where too many clicks from the same user can trigger account suspension. While this rule was put in place to prevent fraudulent activities, it can also have unintended consequences. For example, if attackers know the exact threshold of clicks that will trigger the suspension, they can exploit this vulnerability and use it to generate fraudulent ad revenue. In the end, this could lead to millions of dollars in charges to Google’s customers. Thus, there is a delicate balance between providing enough information to ensure trust in AI systems and not providing so much information that it can be exploited by malicious actors.
Therefore, while interpretability is a valuable tool in many cases, it’s important to recognize that there are situations where it may not be appropriate or beneficial.
Conclusion
In conclusion, interpretability remains a critical challenge for AI systems. As AI continues to become more prevalent in our daily lives, it is important that we understand how these systems arrive at their decisions and predictions. The development of interpretable AI will not only enhance transparency and accountability but also enable better decision-making, reduce biases, and improve overall trustworthiness. The recent advancements in interpretability research have shown significant progress towards achieving these goals, but there is still much work to be done.
As we move forward, it is crucial that researchers, policymakers, and industry professionals work together to ensure that AI systems are transparent and explainable. While there is no one-size-fits-all solution, the continued development and application of human-in-the-loop methods, attention-based models, model distillation, and Bayesian approaches offer promising avenues for future research.
Ultimately, the success of AI in the future will depend on its ability to be trusted and understood by end-users. By prioritizing interpretability, we can ensure that AI systems are not only effective but also ethical and accountable.
Discover more from The Same Tech
Subscribe to get the latest posts sent to your email.
Be First to Comment